Introduction et contexte
Dans le cadre de mon travail, je devais concevoir un outil en Laravel permettant de récupérer les statistiques de nos sites présents sur Cloudflare. Pour cela, j'ai d'abord cherché la documentation de l'API sur le site de Cloudflare, ainsi que des bibliothèques compatibles PHP.
En testant le SDK PHP officiel de Cloudflare, je me suis vite rendu compte de deux choses : Cloudflare ne semble pas vouloir maintenir durablement ce SDK, et une partie des anciens endpoints REST a été remplacée par des endpoints GraphQL.
Pourquoi GraphQL m'a bloqué
N'ayant jamais utilisé d'API GraphQL, j'ai commencé à chercher les endpoints dans la documentation comme je le fais d'habitude pour une API REST.
C'est là que j'ai commencé à me perdre. Contrairement à une documentation REST bien structurée, il m'était difficile de comprendre les noms de champs, les arguments, les périodes temporelles, et surtout les permissions et limites associées à chaque plan.
J'ai donc installé un client GraphQL (Altair) pour tester les requêtes directement.
C'est à ce moment-là que j'ai découvert une fonctionnalité intéressante : l'introspection.
En simplifiant beaucoup, elle permet au client de récupérer le schéma GraphQL depuis le serveur afin de découvrir les requêtes, types, champs, arguments et mutations disponibles.
Sur le papier, c'était parfait. En pratique, c'était trompeur : l'introspection ne connaît pas les permissions réelles de chaque zone, ni les limites propres aux plans gratuit, pro, business ou entreprise. Altair me générait donc des requêtes "valides" en apparence, mais souvent avec trop d'arguments ou des champs auxquels je n'avais pas accès.
À la différence d'une bonne documentation REST, GraphQL demande souvent d'aller chercher soi-même :
- le niveau de permission nécessaire.
- les données réellement disponibles.
- les périodes acceptées.
- les filtres utilisables selon le plan.
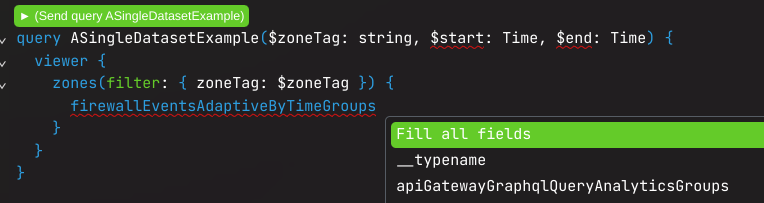
Ce qui génère la requête GraphQL suivante :
query ASingleDatasetExample($zoneTag: string, $start: Time, $end: Time) {
viewer {
zones(filter: { zoneTag: $zoneTag }) {
firewallEventsAdaptiveByTimeGroups {
avg {
sampleInterval
}
confidence(level: "_____") {
count {
estimate
isValid
lower
sampleSize
upper
}
level
}
count
dimensions {
apiGatewayMatchedEndpoint
apiGatewayMatchedHost
attackSignatureCategories
attackSignatureRefs
botDetectionIds
botDetectionTags
botScore
botScoreSrcName
date
datetime
datetimeFifteenMinutes
datetimeFiveMinutes
datetimeHour
datetimeMinute
description
firewallForAiAnyPiiCategory
firewallForAiCustomTopicCategoriesScoresMin
firewallForAiInjectionScore
firewallForAiPiiCategories
firewallForAiUnsafeTopicCategories
fraudAttack
fraudDetectionIds
fraudDetectionTags
fraudEmailRisk
fraudEventType
fraudUserId
httpApplicationVersion
ja3Hash
ja4
jsDetectionPassed
verifiedBotCategory
wafAttackScore
wafAttackScoreClass
wafMlAttackScore
wafMlSqliAttackScore
wafMlXssAttackScore
wafPathTraversalAttackScore
wafRceAttackScore
wafSqliAttackScore
wafXssAttackScore
zoneVersion
}
sum {
botDetectionIdArray
botDetectionIdCountArray
botDetectionTagArray
botDetectionTagCountArray
fraudDetectionIdArray
fraudDetectionIdCountArray
fraudDetectionTagArray
fraudDetectionTagCountArray
}
}
}
}
}
Dont les ¾ sont des données entreprise !
Nous pouvons toute de mettre testé, et supprimé pas a pas les champs et dimensions que nous n'avons pas accès afin d'obtenir une requête qui fonctionne :
query ASingleDatasetExample($zoneTag: string, $start: Time, $end: Time) {
viewer {
zones(filter: { zoneTag: $zoneTag }) {
firewallEventsAdaptiveByTimeGroups(
filter: { datetime_gt: $start, datetime_lt: $end }
limit: 2
orderBy: [datetime_DESC]
) {
avg {
sampleInterval
}
count
dimensions {
date
datetime
datetimeFifteenMinutes
datetimeFiveMinutes
datetimeHour
datetimeMinute
description
firewallForAiAnyPiiCategory
firewallForAiCustomTopicCategoriesScoresMin
firewallForAiInjectionScore
firewallForAiPiiCategories
firewallForAiUnsafeTopicCategories
httpApplicationVersion
verifiedBotCategory
zoneVersion
}
}
}
}
}
Nous pouvons tout de suite voir qu'il
Découverte du MCP Cloudflare
À force de chercher les limites et les contraintes dans la documentation, je suis tombé sur la page du MCP Cloudflare dédiée à GraphQL. Le README contenait des exemples de prompts très parlants, comme :
Show me HTTP traffic for the last 7 days for example.comShow me which GraphQL datatype I need to use to query firewall events
L'idée m'a tout de suite plu : au lieu de passer des heures à deviner les bons champs et les bonnes combinaisons, je pouvais laisser un outil IA explorer le schéma et me proposer des requêtes réellement compatibles avec mon contexte.
Tentative dans le Playground
En découvrant le MCP, j'ai aussi vu que Cloudflare proposait un Playground sous forme de chat. J'y ai connecté le MCP GraphQL et commencé à rédiger les prompts proposés dans le README.
Mais là, catastrophe : le Playground était trop instable dans mon cas. Quand j'essayais de récupérer des statistiques d'un de mes domaines, j'obtenais parfois des erreurs de sécurité ou des réponses inutilisables.
Même quand je demandais explicitement d'utiliser le MCP Cloudflare, le résultat tournait souvent en rond : tentative de passer par HTTP, mauvaise interprétation du contexte, ou requêtes qui n'allaient pas au bout.
J'ai donc vite abandonné cette piste pour passer sur Claude Code.
Passage à Claude Code
Pour ajouter le MCP GraphQL dans Claude Code, on peut le connecter avec :
claude mcp add --transport sse cloudflare-graphql https://graphql.mcp.cloudflare.com/sse
Ensuite, il faut s'authentifier dans les paramètres du MCP.
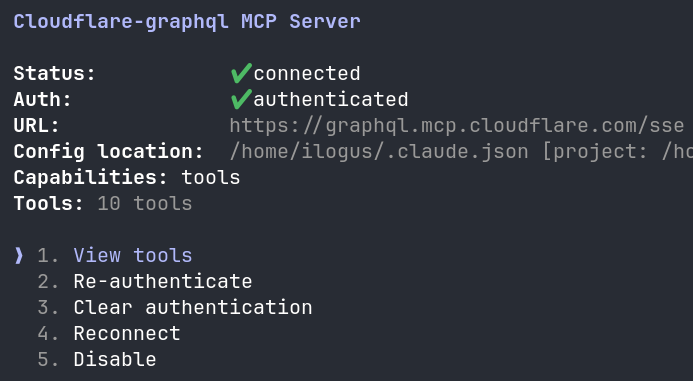
Si vous l'utilisez sur plusieurs jours, vérifiez régulièrement que la connexion est toujours valide.
Une fois connecté, j'ai pu réessayer de récupérer les données que je cherchais au départ.
Et là, cette fois, ça a fonctionné : j'ai obtenu les bonnes requêtes, testées par rapport à mon plan, avec les bons champs et les bons paramètres. Le plus utile, c'est que j'avais enfin des requêtes prêtes à être intégrées dans mon application.
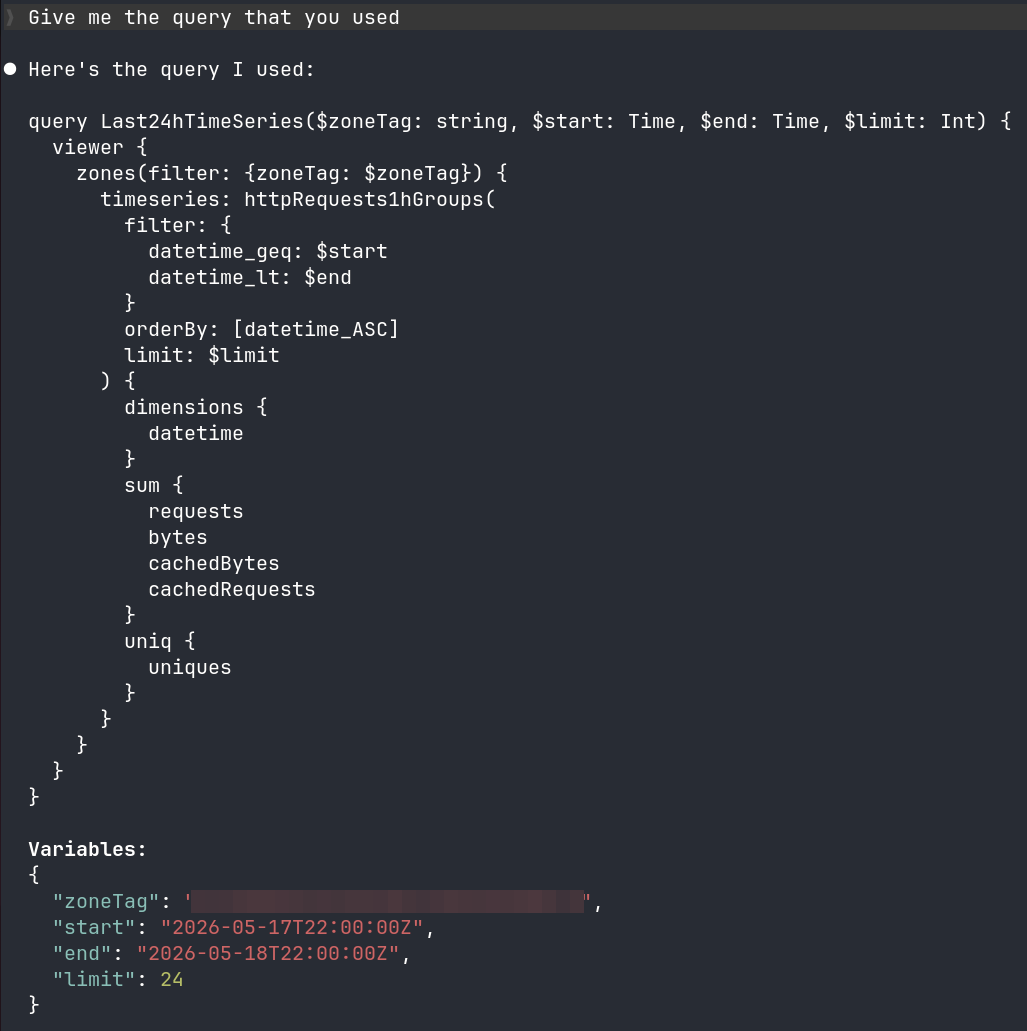
Ce que j'ai retenu
Le vrai gain du MCP n'est pas seulement de "générer une requête". Le gain, c'est surtout de réduire le temps perdu à interpréter une documentation GraphQL trop abstraite.
Dans mon cas, il m'a aidé à :
- identifier les bons champs.
- comprendre les contraintes liées à mon plan.
- tester les paramètres avant l'intégration.
- éviter de partir sur des requêtes trop ambitieuses ou invalides.
Conseils sur l'API GraphQL de Cloudflare
Si vous implémentez cette API, gardez à l'esprit ses limites. D'après la documentation Cloudflare, la GraphQL Analytics API est faite pour des données agrégées, et les limites par défaut incluent notamment 300 requêtes sur une fenêtre de 5 minutes, ainsi qu'un maximum de 10 zones pour une requête zone-scoped.
Si vous devez récupérer des données sur plusieurs zones, le plus propre reste de travailler par batch de 10 zones à la fois. Cela économise grandement le nombre total de requêtes et évite de taper inutilement dans les limites.
Exemple de requête
Une fois la logique comprise, la partie intéressante devient surtout l'intégration dans le code. Voici un exemple de structure de requête GraphQL que j'ai pu stabiliser après les tests avec le MCP :
query FirewallByTimeBatch(
$zoneTags: [string!]
$start: Time
$end: Time
) {
viewer {
zones(filter: { zoneTag_in: $zoneTags }) {
zoneTag
firewallEventsAdaptiveByTimeGroups(
filter: {
datetime_geq: $start
datetime_lt: $end
action: "block"
}
limit: 1000
orderBy: [datetimeHour_ASC]
) {
dimensions {
datetimeHour
}
count
}
}
}
}
# variables
{
"zoneTags": [
"abc123",
"abc456"
],
"start": "2026-05-11T02:07:05Z",
"end": "2026-05-11T17:07:05Z"
}
Le but n'était pas d'avoir la requête la plus élégante possible, mais la bonne requête pour mon besoin réel.
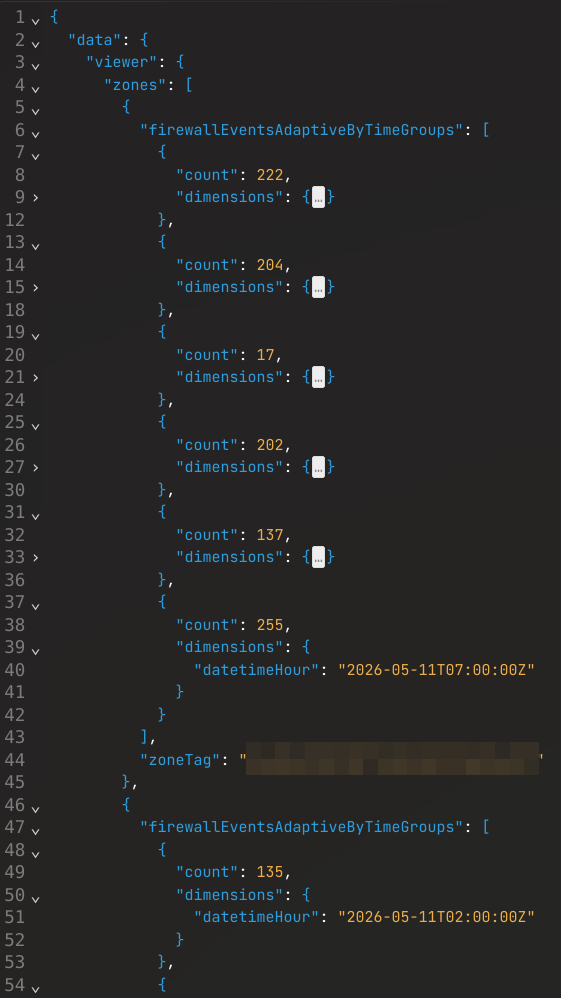
Conclusion pratique
L'API GraphQL de Cloudflare reste puissante, mais la documentation demande clairement plus d'effort qu'une API REST bien balisée. Si vous n'êtes pas à l'aise avec GraphQL, je vous conseille de ne pas perdre trop de temps à deviner les champs et les contraintes à la main.
Utilisez plutôt le MCP de Cloudflare dans votre environnement de développement. Laissez l'IA explorer le schéma, tester les permissions selon votre abonnement, puis générer les requêtes que vous pourrez intégrer ensuite dans votre projet.
C'est, à mon sens, le moyen le plus rapide pour passer d'une documentation confuse à des requêtes réellement exploitables.